Spotlight: Data Driven Design of Polymer-based Biomaterials
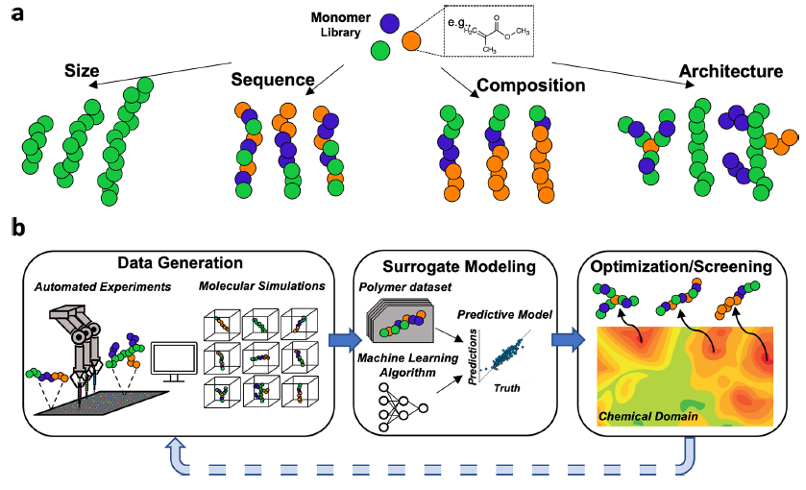
Polymers, with the capacity to tunably alter properties and response based on manipulation of their chemical characteristics, are attractive components in biomaterials. Nevertheless, their potential as functional materials is also inhibited by their complexity, which complicates rational or brute-force design and realization. In recent years, machine learning has emerged as a useful tool for facilitating materials design via efficient modeling of structure−property relationships in the chemical domain of interest. Here, the emergence of data-driven design of polymers that can be deployed in biomaterials is discussed with particular emphasis on complex copolymer systems. These algorithms act as surrogate predictions in lieu of measurements obtained through more costly simulations or experiments, thereby substantially expanding the scope of materials that can be hypothetically probed. Recent developments are outlined related to high-throughput data generation for polymer systems, methods for surrogate modeling by machine learning, and paradigms for property optimization and design. Key aspects of successful strategies and other considerations that will be relevant to the future design of polymer-based biomaterials with target properties are highlighted.
