Impact of Data Bias on Machine Learning for Crystal Compound Synthesizability Predictions
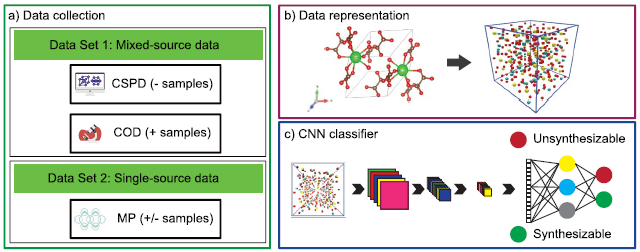
Machine learning models are susceptible to being misled by biases in training data that emphasize incidental correlations over the intended learning task. In this study, the impact of data bias is demonstrated on the performance of a machine learning model designed to predict the likelihood of synthesizability of crystal compounds. The model performs a binary classification on labeled crystal samples.
Despite using the same architecture for the machine learning model, how the model’s learning and prediction behavior differs once trained on distinct data is showcased. Two data sets are used for illustration: a mixed-source data set that integrates experimental and computational crystal samples and a single-source data set consisting of data exclusively from one computational database. Simple procedures are presented to detect data bias and to evaluate its effect on the model’s performance and generalization.
This study reveals how inconsistent, unbalanced data can propagate bias, undermining real-world applicability even for advanced machine learning techniques.
